李宏毅机器学习课程学习记录-2
李宏毅机器学习课程学习记录(二)
回归问题
Regression 就是找到一个函数 function ,通过输入特征 x,输出一个数值 Scalar。
模型步骤
- step1:模型假设,选择模型框架(线性模型)
- step2:模型评估,如何判断众多模型的好坏(损失函数)
- step3:模型优化,如何筛选最优的模型(梯度下降)
过拟合以及欠拟合问题
对于深度学习或机器学习模型而言,我们不仅要求它对训练数据集有很好的拟合(训练误差),同时也希望它可以对未知数据集(测试集)有很好的拟合结果(泛化能力),所产生的测试误差被称为泛化误差。度量泛化能力的好坏,最直观的表现就是模型的过拟合(overfitting)和欠拟合(underfitting)。过拟合和欠拟合是用于描述模型在训练过程中的两种状态。一般来说,训练过程会是如下所示的一个曲线图。
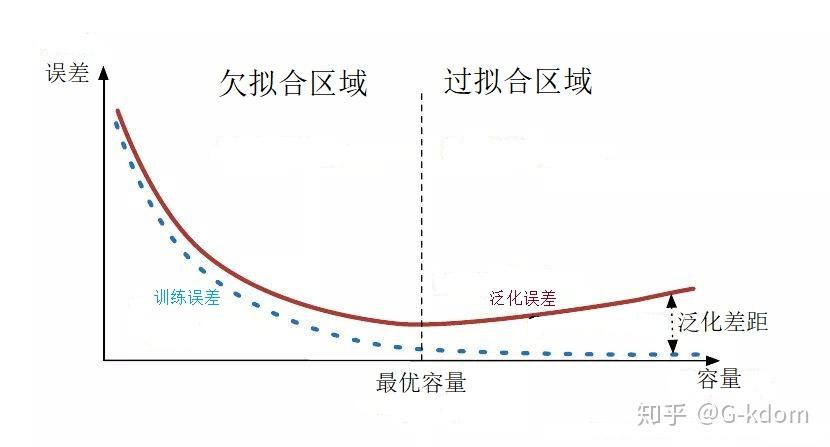
训练刚开始的时候,模型还在学习过程中,处于欠拟合区域。随着训练的进行,训练误差和测试误差都下降。在到达一个临界点之后,训练集的误差下降,测试集的误差上升了,这个时候就进入了过拟合区域——由于训练出来的网络过度拟合了训练集,对训练集以外的数据却不work。
欠拟合:欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在训练集上就表现很差,没法学习到数据背后的规律。
过拟合:过拟合是指训练误差和测试误差之间的差距太大。换句换说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差。模型对训练集”死记硬背”(记住了不适用于测试集的训练集性质或特点),没有理解数据背后的规律,泛化能力差。
Error的来源
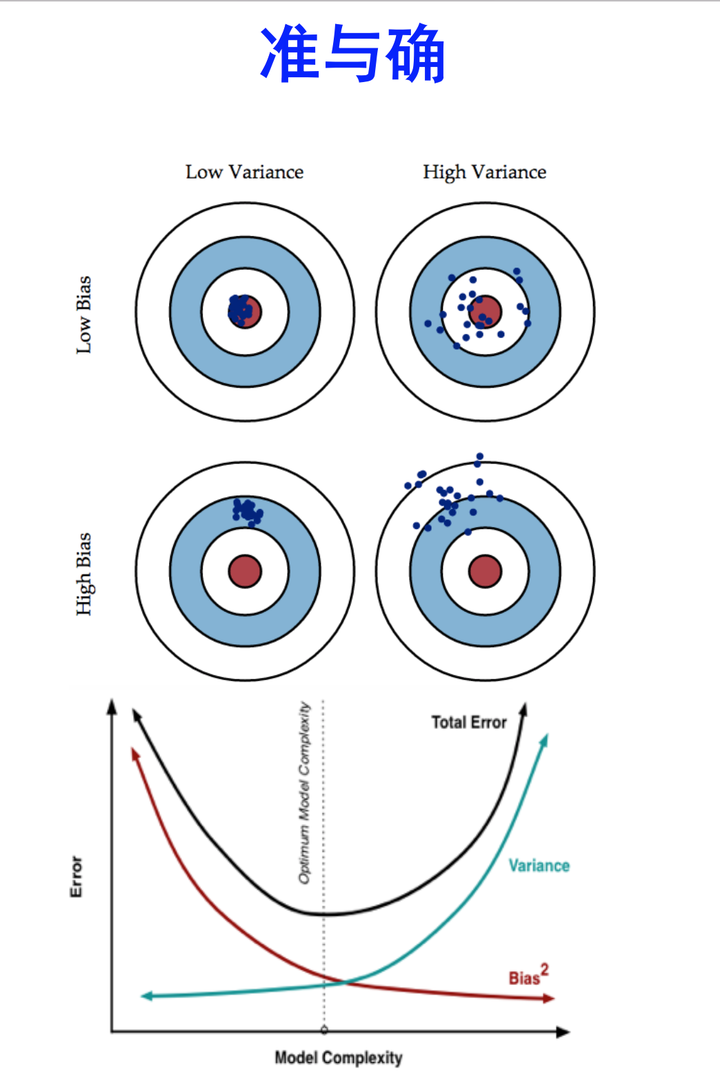
随着模型复杂增加呈指数上升趋势。更复杂的模型并不能给测试集带来更好的效果,而这些 Error 的主要有两个来源,分别是 bias 和 variance 。
Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
Bias vs Variance

模型选择
现在在偏差和方差之间就需要一个权衡 想选择的模型,可以平衡偏差和方差产生的错误,使得总错误最小 但是下面这件事最好不要做:

用训练集训练不同的模型,然后在测试集上比较错误,模型3的错误比较小,就认为模型3好。但实际上这只是你手上的测试集,真正完整的测试集并没有。比如在已有的测试集上错误是0.5,但有条件收集到更多的测试集后通常得到的错误都是大于0.5的。
交叉验证

图中public的测试集是已有的,private是没有的,不知道的。交叉验证 就是将训练集再分为两部分,一部分作为训练集,一部分作为验证集。用训练集训练模型,然后再验证集上比较,确实出最好的模型之后(比如模型3),再用全部的训练集训练模型3,然后再用public的测试集进行测试,此时一般得到的错误都是大一些的。不过此时会比较想再回去调一下参数,调整模型,让在public的测试集上更好,但不太推荐这样。
上述方法可能会担心将训练集拆分的时候分的效果比较差怎么办,可以用下面的方法。
N-折交叉验证
将训练集分成N份,比如分成3份。

比如在三份中训练结果Average错误是模型1最好,再用全部训练集训练模型1。
梯度下降法
η 叫做Learning rates(学习速率)

如何找到最优的值
一、调整学习速率
心翼翼地调整学习率
举例:

上图左边黑色为损失函数的曲线,假设从左边最高点开始,如果学习率调整的刚刚好,比如红色的线,就能顺利找到最低点。如果学习率调整的太小,比如蓝色的线,就会走的太慢,虽然这种情况给足够多的时间也可以找到最低点,实际情况可能会等不及出结果。如果 学习率调整的有点大,比如绿色的线,就会在上面震荡,走不下去,永远无法到达最低点。还有可能非常大,比如黄色的线,直接就飞出去了,更新参数的时候只会发现损失函数越更新越大。
虽然这样的可视化可以很直观观察,但可视化也只是能在参数是一维或者二维的时候进行,更高维的情况已经无法可视化了。
解决方法就是上图右边的方案,将参数改变对损失函数的影响进行可视化。比如学习率太小(蓝色的线),损失函数下降的非常慢;学习率太大(绿色的线),损失函数下降很快,但马上就卡住不下降了;学习率特别大(黄色的线),损失函数就飞出去了;红色的就是差不多刚好,可以得到一个好的结果。
自适应学习率
举一个简单的思想:随着次数的增加,通过一些因子来减少学习率
通常刚开始,初始点会距离最低点比较远,所以使用大一点的学习率
update好几次参数之后呢,比较靠近最低点了,此时减少学习率
学习率不能是一个值通用所有特征,不同的参数需要不同的学习率
二、随机梯度下降法

三、特征缩放
参考文献:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!